2023年12月5日(火) 17時15分から17時40分頃まで、弊社サービスであるクラスメソッドメンバーズに加入いただいている一部のお客様のAWSアカウントにてAWSリソースに対する各種操作ができない状況となりました。お客様のビジネスに多大な影響を及ぼした可能性があることを心よりお詫び申し上げます。
なお、影響を受けた可能性のあるAWSアカウントをお持ちのお客様には担当者様宛にメール等にてご報告済みです。
[事後検証(ポストモーテム)の公開理由]
今回発生した障害において、ポストモーテムを公開いたします。この決定は、主に以下の二つの理由に基づきます。
透明性の確保:私たちは、透明性を重視しており、障害の原因と対処方法を公開することで、このコミットメントを示したいと考えています。
内部プロセスの改善:障害の分析を行い、それを共有することで、内部のプロセスとシステムの改善につなげることと、将来的な類似の問題を防ぐことを意図しています。
AWS環境における通常時作業フロー
弊社における AWS Organizations の運用(顧客のアカウント管理やセキュリティ等の確保のために、事前に確立した手順による運用作業)では、組織ユニット(Organizational Units、以下 OU)やサービス制御ポリシー( Service Control Policies、以下 SCP)の作成や修正を、弊社システムにより実施し、これらの修正内容はレビューおよび承認プロセスを通じて確認されています。
お客様が所有するAWS 環境での作業の場合は、対応フローが定義され、手順書の作成および有識者による確認を行い、加えて自動化も実施しています。これらのプロセスは、権限分離、局所化、ワークフロー等を考慮した設計に基づいており、定期的な社内外の監査や見直しを継続的に行っております。
しかしながら今回の事象は特定の顧客向けの緊急対応により特殊な手順での作業を実施したことから、作業上のミスが発生しました。
なお、本事象は外部からの攻撃や内部犯行によるものではなく情報漏洩やシステム侵害は発生しておりません。
発生の経緯
本障害が発生した作業は、特定のお客様から特定 AWS アカウント群を一時的に閉鎖する要望をいただいたことによります。セキュリティインシデントに対するフォレンジック調査の一環であり、弊社としては可能な限り早く対応する必要があると判断しました。
要望にはお客様が認識できていない外部からのアクセスやAPIによる操作を完全に止めたいという内容が含まれており、弊社内で要望を満たす手段を検討した結果、対象の AWS アカウントを隔離するために新規 OU を作成し、操作を禁止する(Deny *) SCP を適用することが適切だと判断しました。
今回の作業は通常運用と異なる特別な対応となりました。本特例対応では、作業者には必要とされる最低限のAWS Organizationsに対するアクセスのみを付与しております。作業経験のある担当者二人によるダブルチェック体制でのマネジメントコンソールでの作業を実施しました。作業内容を決定後、弊社のテスト環境にてSCP 内容およびOU構成に問題がないかを確認しました。
--------------------------------------------------------
<2023年12月14日 追記>
障害の発生原因となった特例対応作業の経緯詳細について
フォレンジック調査対象の AWS アカウントは20以上あり、これらのアカウントには多数の AWS アカウントへのログイン権限(IAM ユーザーやIAMロール)が存在していました。私たちの目的は、AWS の全サービスの動作を停止し、これ以上の被害拡大を防ぐことでした。
以下の選択肢に対する検討を行いました。
・ IAM ユーザーおよび IAM ロールに個別に制限をかける: IAM ユーザーと IAMロールに対し個別に 制限ポリシーを適用する方法です。この選択肢は、対象権限数が多く、期限内に作業を完了できないと判断されたため見送られました。
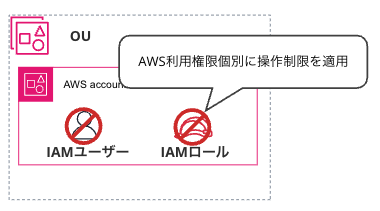
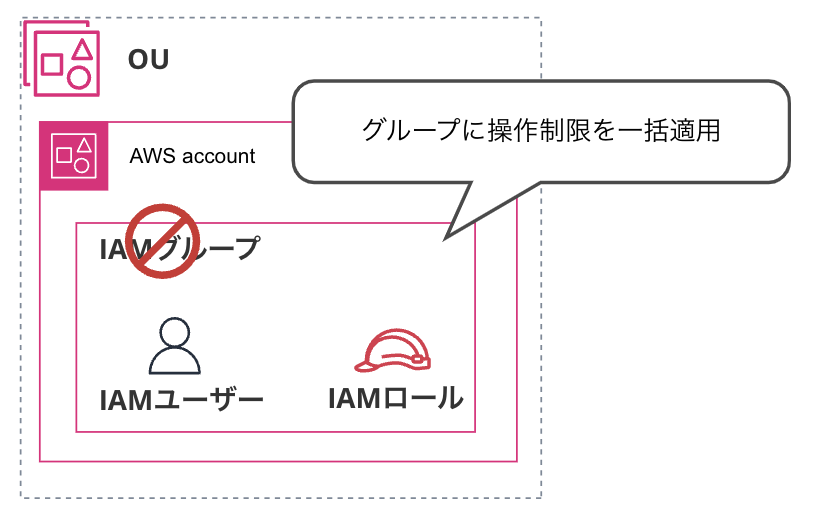
・IAM ユーザーを IAM グループ化して制限をかける: IAM グループを作成し 制限ポリシーを適用する方法です。このグループに IAM ユーザーを所属させます。この選択肢は、IAM ロールへの適用ができないため、この方法も見送られました。
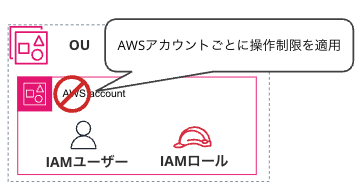
・個別 AWS アカウント単位で制限をかける: AWSアカウントを一括管理するOrganizations 機能で 個別 AWS アカウントに 制限ポリシーを適用します。ポリシーの適用数制限に抵触する可能性を考慮しこの選択肢は見送られました。
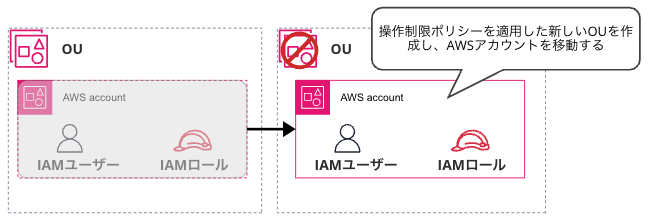
・組織単位でAWS アカウントに制限をかける: AWSアカウントを一括管理するOrganizations 機能で 専用の OU(AWS アカウントをまとめるグループ)を作成し グループに制限ポリシーを適用する方法です。まだ制限が掛かっていない状態の OU へ対象 AWS アカウントを移動し、対象 AWS アカウントのみが隔離されたことを確認した上で 制限ポリシーを適用することで影響範囲を限定した対応が可能と判断しました。
この作業とは別に、EC2 などのリソース停止が必要になります。この作業は、IAM 権限剥奪後に行う必要があります。先に IAM 権限を剥奪しない場合、攻撃者によるリソース起動ができてしまうためです。
--------------------------------------------------------
作業時の状況
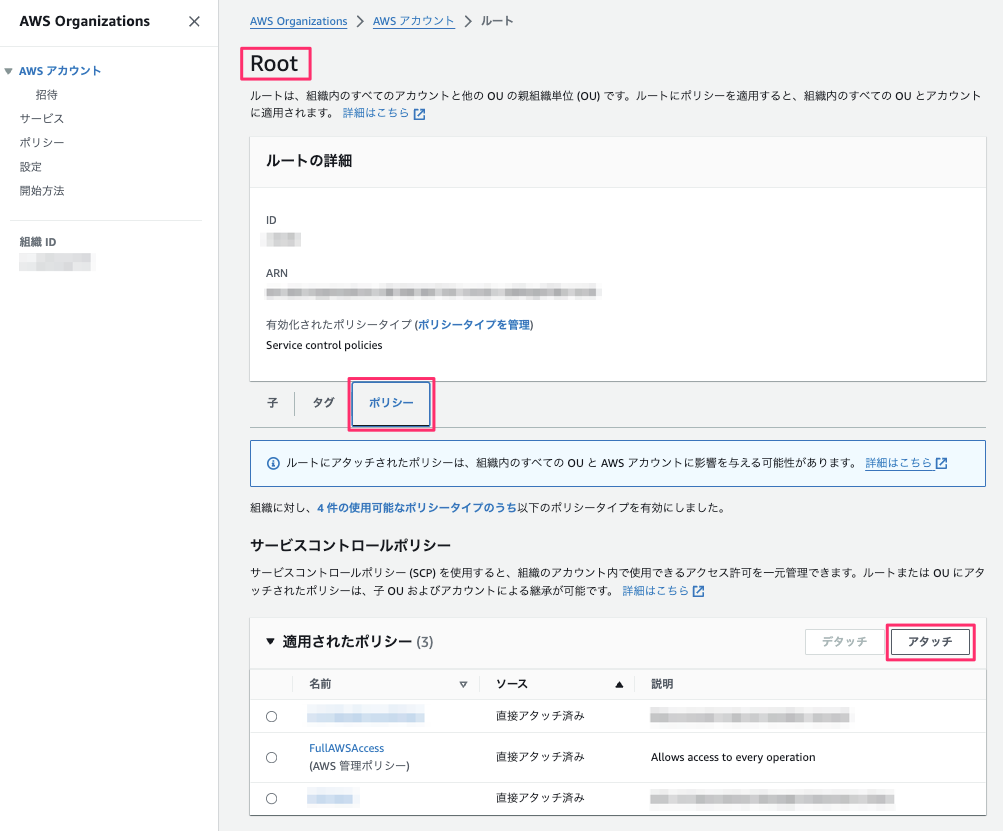
2023年12月5日17時5分、本番環境に変更を加える作業を実施するためマネジメントコンソール(AWS Organizationsのページ)にて操作を禁止する SCP を新規に作成し、最上位に設定されている組織(Root OU) を選択し新しい OU を作成しました。
しかし、作成した OU を選択(画面遷移)せずに、Root OU が選択された状態で SCP をアタッチする作業を行いました。作業者およびダブルチェック者が画面上で選択されている OU の確認が漏れていたため、本事象が発生しました。
Root OU に 、操作を禁止する(Deny * ) SCPがアタッチされ作業対象の AWS アカウント以外でも操作不能となりました。
時系列の報告
2023-12-05 17:05
操作者・確認者の2名を作業にアサイン。
複数のお客様が含まれる Organizations において以下作業を実施。
・全ての操作を禁止する SCP を作成。
・特定の AWS アカウントだけを対象とするために OU を作成。
2023-12-05 17:15
作成した OU に対してSCP を適用すべきところを、誤って Organizations の Root OU に適用し、Organizations 内の全ての AWS アカウントの操作ができなくなった。
2023-12-05 17:27
お客様からの問い合わせにより障害発生を認知。
障害状況の調査を開始。
2023-12-05 17:36
障害状況から原因が本作業であることを特定。
2023-12-05 17:38
切り戻し作業を実行。
・Root OU から原因となっていた SCP を解除。
2023-12-05 17:40
対策を完了し、障害が復旧していることを確認。
2023-12-05 17:51
メンバーズポータルのお知らせ一覧ページにて障害速報を公開。
2023-12-06 19:30
対象 AWS アカウントの登録済み技術通知先宛にメールおよびメンバーズポータルにて障害の詳細を報告。
2023-12-06 20:30
事後検証報告(本文書)をホームページ上で公開
原因分析と今後の対応
今回の事象はフォレンジック調査に関する対応フローが確立されていなかったため、個別対応を行った結果発生しました。
また、今回はOUレベルで分離を行いましたが、本来であれば既存 AWS Organizationsに影響がないよう、新規作成した管理アカウントによるAWS Organizationsレベルの分離が適切でした。
今後は、OUの操作において、同様の問題が決して発生しないように、Root OUへの操作ができないように権限の局所化を実施いたします。
本事象において、弊社では再発防止策のため以下の対応を行います。
特例対応(緊急時の暫定対応)時のプロセスを定義し、担当者の操作による作業の場合、必ず手順書を作成しテスト環境における動作確認を行い責任者によるレビューおよび承認を必須とします。
特例対応発生のリスク報告および作業実施承認フローを明文化したドキュメントを作成し運用します。
さらに、レビューの観点を明確にし、影響範囲を局所化、回避、分離することで、作業リスクを低減します。
再現性のあるレビュー可能な状態を作り出すことにより、特別な対応が必要な場合に担当者だけの判断に頼ることなく、事故の防止と責任者による作業監査の確実な実行を可能にします。
また、フォレンジック調査における対応手順を確立し、特例対応ではなく通常対応とします。
--------------------------------------------------------
<2023年12月14日 追記>
具体的な再発防止策
本障害の本質的な原因は、リスク評価の不足(特に特例対応時には全社的な対応が必要な事例であったかどうかの評価が十分でなかったこと)およびリスク最小化の不十分さ(操作ミスが発生しても影響が最小限に抑えられるよう、権限の局所化や分離などが不十分であったこと)にあると考えられます。これらに焦点を当てた対策を策定しました。
フォレンジック調査に関する対応の標準化
フォレンジック調査に関する対応手順を確立し、標準運用手順として属人化を排除します。
今回の問題では、影響の局所化が考慮されていないことで被害が拡大しました。
弊社メンバーズでお預かりしているAWSアカウントはOrganizations 機能によりグループとして管理されています。このグループを管理する単一アカウント(管理アカウント)への設定変更が障害発生の契機でした。
障害発生までの流れは以下となります。
1.管理アカウントに所属する一部のAWSアカウントにのみ制限をかけることを目的としました。
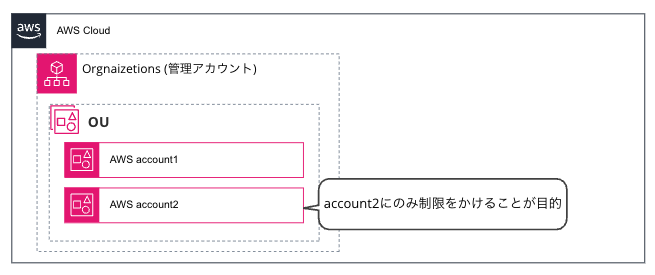
2.OUを新規に作成し、制限をかけるアカウントを移動しました。この作業は、特例作業用のIAMロールを作成し、作業者に権限が付与されていました。
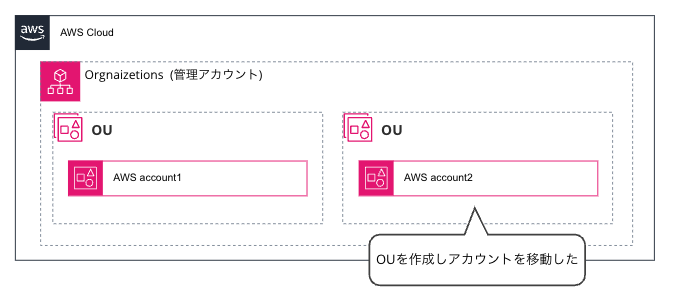
3.制限ポリシーを新規作成したOUに適用するべきところ、管理アカウント全体(root OU)に適用しました。

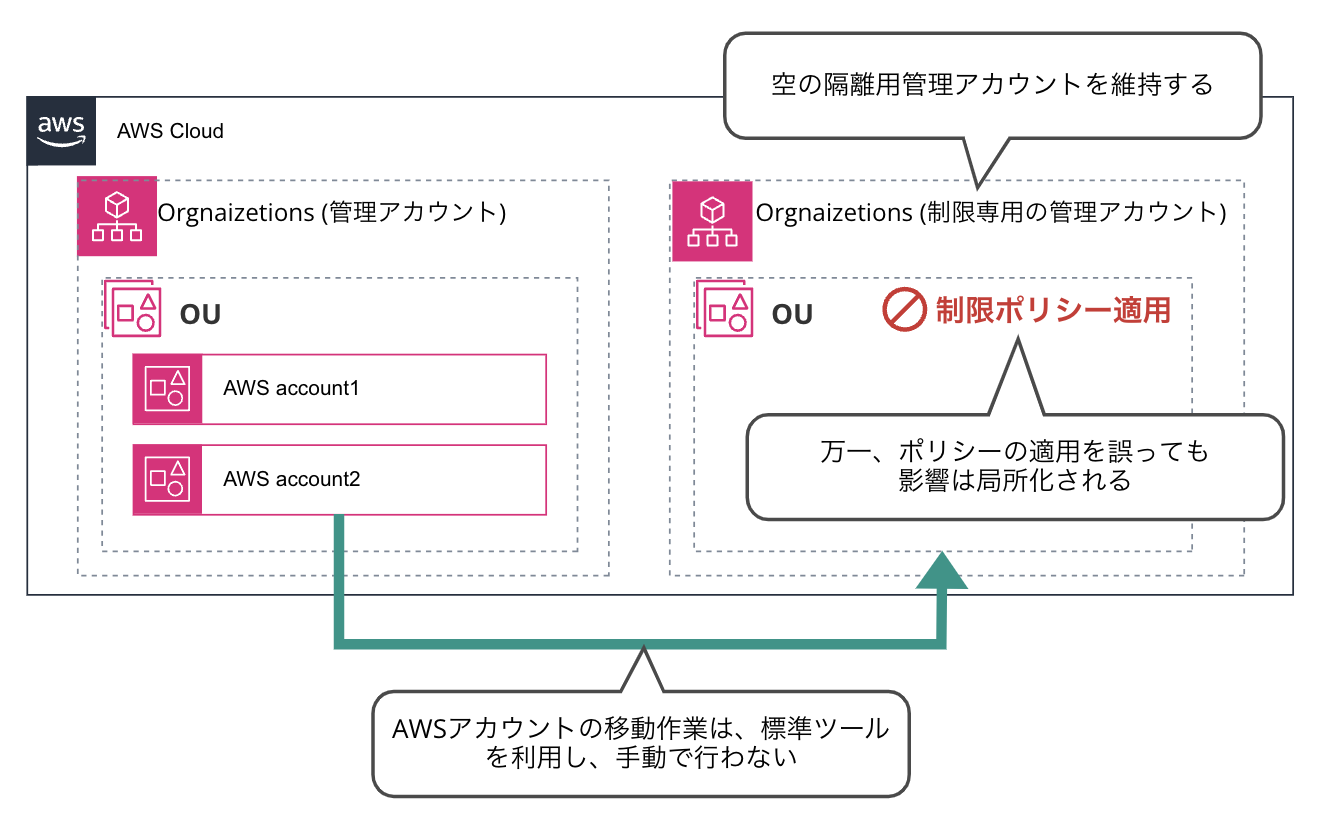
このため、影響の局所化の観点から以下の2点を実施致します。
フォレンジック調査対応専用の管理アカウントを事前に準備し作業影響の分離を行います。管理アカウントの設定は配下にのみ影響があるため、万一、設定を誤っても影響は局所化され、他のAWSアカウントへの影響は発生しません。
また、管理アカウント間でのアカウント移動作業を、通常作業として日常的に実施している安全性の確認および標準化された専用ツールと手順により行います。この通常作業は、管理アカウント配下全てのアカウントに影響のあるOU(Root OU)に対する操作ができないように検証されており、本障害と同様の問題は発生しません。これにより、特例作業用IAMロールの発行が不要となり、例外的な権限付与は行われなくなります。
改善後のイメージは以下となります。
フォレンジック調査に関する対応については12月中にドキュメントが作成され、標準手順書として運用が開始される予定です。
--------------------------------------------------------
<2023年12月21日 追記>
フォレンジック調査に関する対応のドキュメントを作成し、標準化が完了しましたので、2024年1月から運用を開始します。
今後、フォレンジック調査における手法や支援を含めたメニューの提供を検討していきます。
--------------------------------------------------------
特例対応の再発防止策
管理アカウントの設定変更の標準対応においては、全て以下のように手動作業が介入しない設計となっています。
・Organizations に関する設定値のコード化
・git によるコード管理および権限統制
・専門の有識者による設定レビューフローの確立
・専用ツールによる本番環境への自動デプロイ
■標準対応の流れ
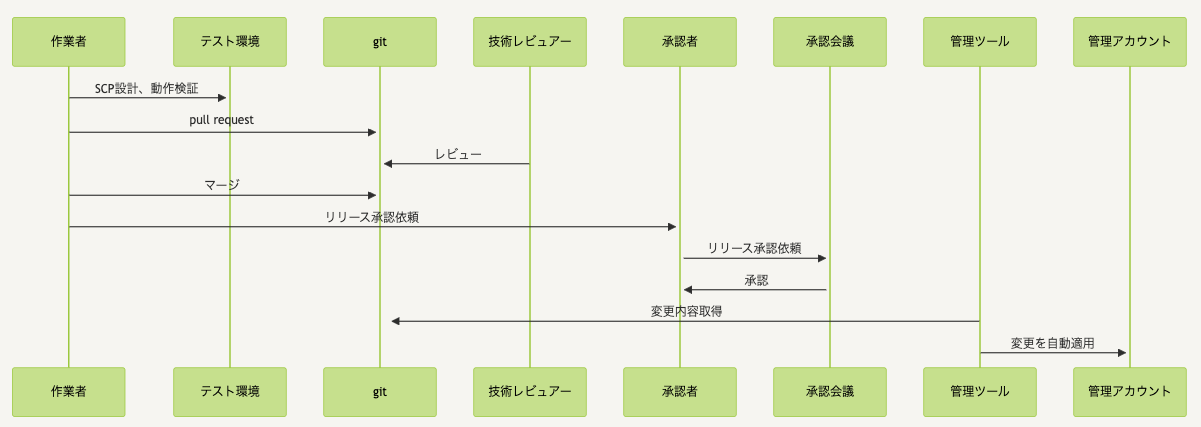
しかし、今回の障害においては、特例作業として標準プロセスから外れた作業が必要となり、手動作業により Organizations の設定値の変更を実施いたしました。
障害発生時の作業フローを以下に示します。
■障害発生時の特例対応の流れ
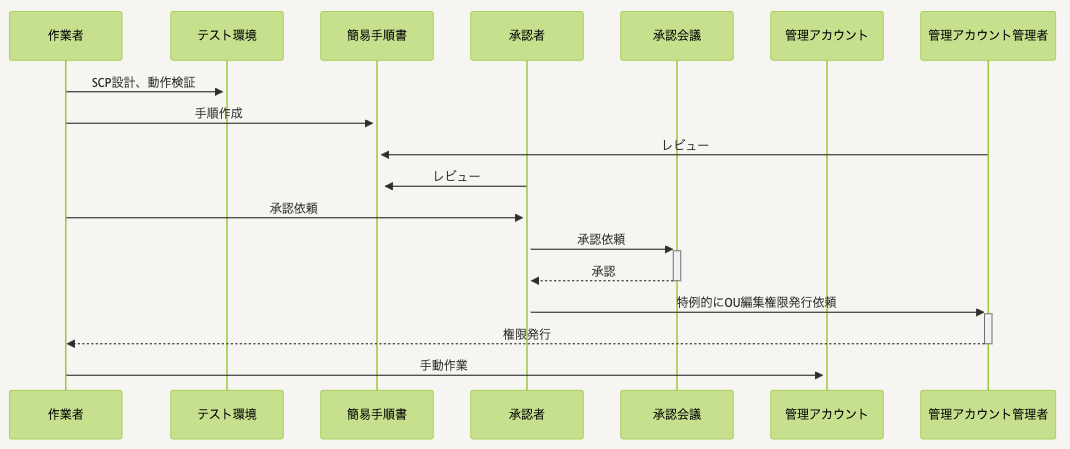
マネージャーを含む4名が設計および実作業を担当する体制を取り対応を行いました。この中で以下のリスク対策が不足していました。
・作業設計において、作業影響が局所化されたものになっていなかった。
・付与されたIAMロールによる作業権限が最小化されていなかった。
・作業手順が詳細化されないことで、作業再現性が低い状態であった。
・ビジネスリスクを有する問題であることが担当者に認識されていなかった。
私たちはこの問題を解決するために、次のプロセスを定義します。
■特例対応発生時の対応の流れ
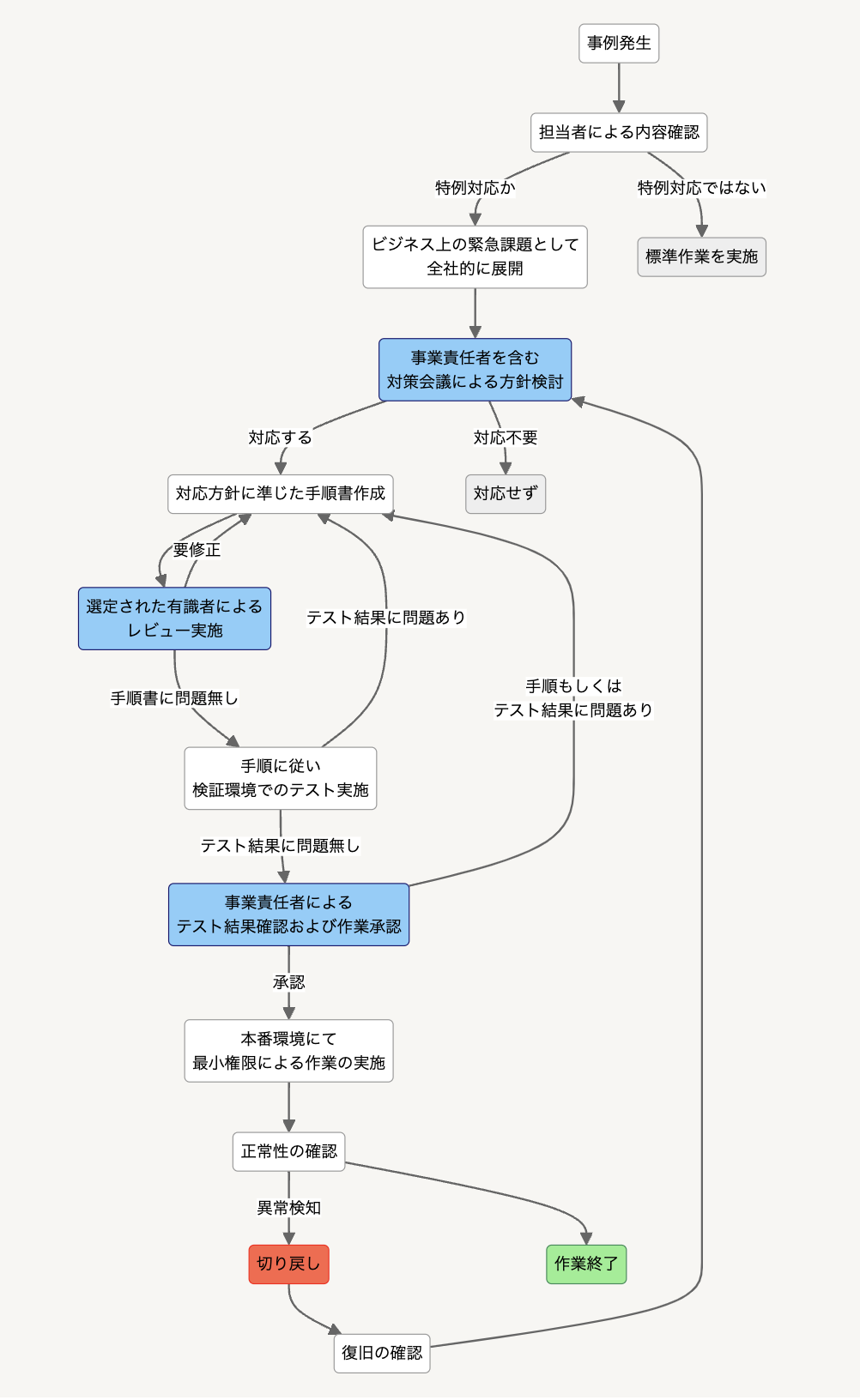
・標準作業で対応できない特例対応が発生した場合、ビジネス上の緊急課題として取り扱われ、ツールにより発生周知および対応手順が全社的に展開されます。
・事業責任者を含む関係者との対策会議を行い、リスク評価の上、対応についての方針を決定し、ドキュメント化します。
・対応方針に沿って、作業手順の作成が行われます。この作業手順書は複数部署に展開され、多数の有識者に共有されます。選定された有識者がレビューします。
・検証環境でのテスト実施を行いその証跡を持って、事業責任者により結果に問題がない事を確認後、作業が承認されます。
・対応方針により選出された、最小権限を持つ習熟した複数名の作業者が作業を実施します。
・作業後に、作業計画により事前定義した正常性の確認を実施し、問題の発生を早期検知します。
・作業による問題が発生した場合は、作業計画により事前定義した切り戻し手順を実行し行い、万一の場合の被害拡大を抑制します。
・作業手順書のレビュー観点を以下に設定し、この項目が網羅された文書フォーマットが用いられます。
- リスク評価に従ったリスク軽減ができているか
- テストされた環境は本番環境相当か
- テスト項目および結果が十分か
- 影響範囲が最も最小化された手段となっているか
- 標準プロセスで対応が可能ではないか
- 操作はコード化を原則とし再現性があるか
- 手動手順が必要な場合は誤操作を誘発しない手順となっているか
- 切り戻し手順が定義されているか
- 正常性の確認手順が定義されているか
- 作業者に付与された権限レベルは最小のものか
- 作業実施タイミングがリスク軽減できているか(金曜日の夕方回避など)
- 顧客への事前連絡が必要な作業か
特例対応におけるワークフロー導入および作業手順書フォーマットは1月中に作成され運用開始する予定です。
--------------------------------------------------------
<2024年2月1日 追記>
・特例対応におけるワークフロー導入および作業手順書フォーマットの整備が完了し、運用が開始されました。
--------------------------------------------------------
基本的には特例対応を最小限に留める方針としつつも、実施が不可避となった場合には、全社的なレビューと影響範囲の最小化を徹底的に行います。さらに、影響を受ける可能性があるお客様に対しては、事前に適切な情報共有を行い、円滑な対応を図ります。
また、本障害を契機にメンバーズの運用作業においてリスク管理不足および権限管理が適切に行われているか改めてチェックを行います。
今後、本障害に対する対応チームは、再発防止策が適正に運用されているか監査し、対策の有効性について評価を行いご報告をいたします。その責任において対策完了を確実に実施することをお約束します。
--------------------------------------------------------
当社は、本事象によりお客様のビジネスに多大な影響を及ぼした可能性があることを深く認識しており、心よりお詫び申し上げます。プロセスの見直しと再発防止に務め、安心してご利用いただけるサービスのご提供のために尽力いたします。
================================
再発防止策の評価結果
本事故に対する再発防止策の有効性について、評価結果を以下の通りご報告いたします。
1. 範囲
2024年2月1日から2024年10月31日までの期間を対象。
2. 特例対応の発生
期間内に3件の特例対応が発生しました。
3. 特例対応フローの実行状況
発生した全てのケースにおいて、事前に定義された対応フローが正常に実行されました。以下に各事象に対する対応フローの詳細を示します。
対応1: 定義されたフローに従い、適切に対応が行われました。
対応2: 定義されたフローに従い、適切に対応が行われました。
対応3: 定義されたフローに従い、全社レビューにより実行不要と判断されました。
4. 対応品質のレビュー
3件の事象について、レビュープロセス、承認プロセス、作成された運用手順書の確認を行い、定義に沿った品質であることを確認しました。
5. 結論
本監査の結果、本事故に対する恒久対策が有効に機能していることが確認されました。
更新履歴
2023年12月6日(水) 初版公開
2023年12月14日(木) 更新
・「発生の経緯」に下記を追記しました。
- 障害の発生原因となった特例対応作業の経緯詳細について
・「原因分析と今後の対応」に下記を追記しました。
- 具体的な再発防止策
- フォレンジック調査に関する対応の標準化
- 特例対応の再発防止策
・「時系列の報告」を詳細化しました。
2023年12月21日(木) 更新
・フォレンジック調査に関する対応のドキュメント作成と標準化の完了について追記しました。
2024年2月1日(木) 更新
・特例対応におけるワークフロー導入および作業手順書フォーマットの整備の完了と、運用開始について追記しました。
本件を持って本障害における恒久対応を完了とさせていただきます。サービスオペレーションの維持・改善は今後も継続的に行い、引き続きサービス品質の向上に尽力いたします。
2024年11月19日(火) 更新
・再発防止策の評価結果を追記しました。