
東京電力エナジーパートナー(以下、東電EP)は2015年に設立した東京電力の100%子会社で、東京電力グループの小売電気事業・ガス小売事業を担っています。小売電気事業者としては日本最大規模です。同社のDXに関する取り組みの1つに、顧客接点となるコールセンター業務の効率化があります。
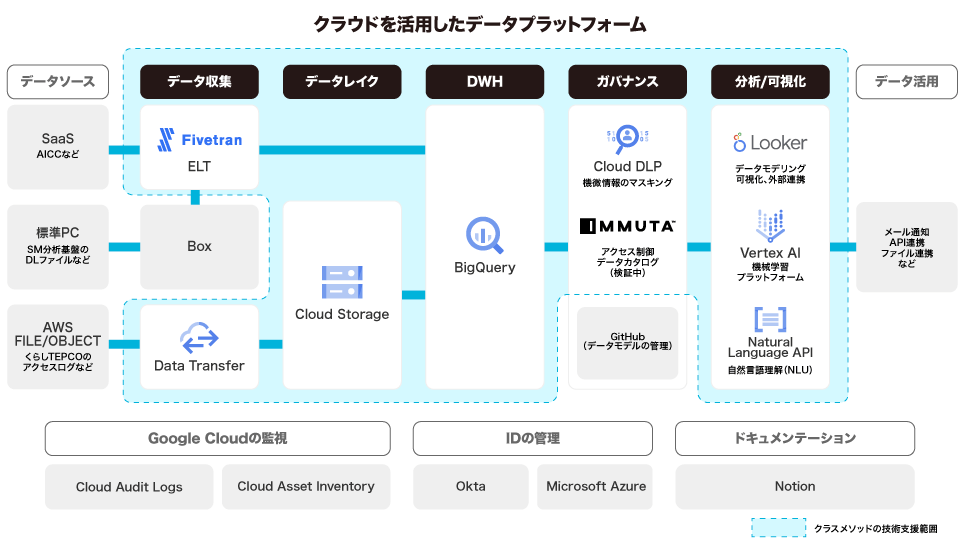
クラスメソッドは東電EPがLookerに着目した2021年5月から、BigQueryを中心としたGoogle Cloud環境構築をサポートしています。そして、コールセンターで蓄積しサイロ化した様々なツールのデータを分析する基盤「EPモダンデータプラットフォーム」を構築。前述のサービスに加え、点在する複数のソースからFivetranを使った一元的なデータ収集など、SaaSを複合的に活用し効率の良いモダンデータスタック環境を実現させました。
今回の取り組みと展望について、オペレーション部門における長い経験からビジネス視点でDXを主導する同社 DX推進室 飯塚 孝高さんにおうかがいしました。

各種クラウドサービスをコールセンターに導入
2016年の電力小売全面自由化、翌年のガス小売全面自由化で、一般家庭も電力やガスの契約を自由に選択できるようになりました。自由化で市場が活性化するなか、それぞれの小売事業者はいっそう顧客接点を重視する必要に迫られています。なかでもコールセンターは引越に伴う契約手続きや、日々の問い合わせが多く寄せられます。東電EPでは、いかに顧客を待たせることなく、必要な手続きや回答を円滑かつ迅速にできるよう、様々な改善を続けています。
「一般的にはトレードオフとみなされがちですが、顧客満足度を下げることなく、業務効率を高めることが課題でした。市場が複雑化していくなか、お客さまの声をうまく拾うことでビジネスにつなげたい。同時に業務効率も飛躍的に高めていきたい。なかでもコールセンターではコストがかかるところですので、オペレーション業務を効率化するためのプロジェクトを進めていました」(飯塚さん)
実際、同社はコールセンター業務効率化のためにSaaSやクラウドサービスを導入してきました。例えばカスタマーサービスのソリューションとしてZendeskを、コンタクトセンターの最適化にAmazon Connectや音声認識としてIBM Watsonなど、それぞれが持つ最新の機能を駆使することで、適所効率化を積極的に進めてきました。
「コールセンターのオペレーション効率化に役立つクラウドサービスを次々に導入し、継続的に改善を続けてきました。しかし集まってくるデータは分散(サイロ化)しているのが問題でした。サービスごとにダッシュボードやデータを可視化する管理画面はあるのですが、複数照らし合わせないとわからないことが多く、新たに導入した施策の効果測定をしようとしてもデータを組み合わせる必要があり、面倒でした」(飯塚さん)
サービス単体ではうまく機能しても、複数のサービスに渡りデータを扱おうとする途端にそのハードルが上がります。過去にはオンプレミス環境に蓄積したデータを取り寄せるのに5ヶ月近くかかったこともありました。これでは新しい施策を試したくても、俊敏に動けません。コールセンターに関するデータを統合的に扱うためには、それぞれのサービスのデータを横断的に分析できる基盤が必要でした。
データモデル管理や外部連携に強いLookerに着目
データ活用の糸口として飯塚さんが目を付けたのがGoogle Cloudの次世代BIプラットフォーム「Looker」でした。データ可視化のほか、データモデル管理や外部連携に強いところが、各種データを統合的に分析する時に有効です。
Lookerが扱える技術パートナーを飯塚さんが探した結果、クラスメソッドが候補のひとつに上がりました。各社のなかから最終的にクラスメソッドを選んだ理由として「レスポンスが早かったのと、小回りが利きそうだったから」と言います。
ほかにも、分析の前段にあたるデータの収集においてもクラウドベースの「Fivetran」を活用。同社の業務ツールにより出力されたデータの抽出・変換を手軽にDWHへ連携できるよう導入しました。
EPモダンデータプラットフォーム構築に向けて、まずはDX推進室を中心にLookerやFivetranに関する情報共有、そしてハンズオンを含むトレーニングを開始しました。続いてBigQueryを中心としたデータ基盤をGoogle Cloudで構築するためのPoCを進めていきました。ここではオンプレも含む既存環境にあるデータロードやデータ整備も含まれます。最終的にはLookerを活用して、データを統合的に活用できる環境を整えることを目指しました。
先述したように、データは分散していました。例えばコールセンターはAmazon Connectを利用しており、音声からテキストに変換したデータはAmazon S3に蓄積していました。また契約などの基幹システムのデータはオンプレにありました。そこでクラスメソッドがデータパイプラインの構築を進めました。また他にもBigQueryテーブルの作成、新たなGoogle Cloud環境の構築支援、機械学習のBQMLやVertexAIなどの活用支援などを、クラスメソッドの専門家がそれぞれ担当しました。また、Immutaによるデータガバナンスも導入を視野に検証が進んでいます。
WebサイトのFAQやチャットボットの改善に貢献
今回構築したのはモダンデータスタックですので、何らかの単一のシステムやアプリケーションではなく、その土台となるものです。モダンデータスタックにより、業務に関連するデータをこれまでよりも素早く取り出せて、柔軟に扱い、分析できるような下地が整いました。まだ正式稼働を開始したばかりですが、モダンデータスタックは業務効率化で効果をじわじわと発揮し始めています。
例えば、各種問い合わせのFAQページには「この記事は役に立ちましたか?」という簡単なアンケートが用意してあります。ここで「はい」のボタンが押される割合は長らく約30%のままでした(問題が解決できたとしても、ボタンを押さずにページを閉じてしまう人もいるためです)。
しかしここに変化が起きました。EPモダンデータプラットフォーム構築時に、FAQページで「いいえ」を選択した場合に「役に立たなかった理由を教えてください」とフィードバックをもらうためのページを作りました。ここに顧客が記入したコメントを自然言語処理でポイントを集約して、結果をLookerのダッシュボードに表示させてFAQを運用しているメンバーが閲覧できるようにしました。するとFAQページの説明文を効果的に改善することができたのです。
「満足度(問合せに「満足している」と回答)の目標を50%に掲げたものの、当初は『無理では?』の声が優勢でした。なにしろ何年も30%のままでしたから。しかし始めて間もなく50%に上昇しました。驚きました。ちゃんとお客さまの声を自然言語処理で上手に分析すれば、結果を出すことができるのだと気づかされました」(飯塚さん)
また東電EPではお客さまからの問い合わせに対応するチャットボットも導入しています。新しい手法なので、チャットだけで問い合わせが完結する割合はそう高くありません。しかし同じく問い合わせ履歴の分析を続けながら、提示するメニューや応答の改良を続けています。EPモダンデータプラットフォーム構築前に比べて、チャットボットだけで問い合わせが完結した割合が約1割向上したそうです。
Webページやチャットボットで解決すれば、その分コールセンターで対応するオペレーターが少なくてすむため顧客満足度と業務効率化の両方を実現できます。
なおWebページの説明文やチャットボットの改善は実に地味な努力の積み重ねが必要です。まだEPモダンデータプラットフォームを導入して間もないなか、成果が数字で表れています。今後はデータ分析や自然言語処理を駆使することで、さらなる向上が期待できます。
コールセンターの枠を超えて全社的なデータ活用基盤へと
 今後の展望について飯塚さんは「もともとコールセンターのオペレーション業務効率向上という課題を解決することが目的にありましたので、ここは継続して取り組みたいと思います。今後はSNSなどのデータも取り込んで分析していこうと考えています」と話しています。
今後の展望について飯塚さんは「もともとコールセンターのオペレーション業務効率向上という課題を解決することが目的にありましたので、ここは継続して取り組みたいと思います。今後はSNSなどのデータも取り込んで分析していこうと考えています」と話しています。Webページやチャットボットの改良でデータ活用効果やの手応えをつかんだ飯塚さんは「あとはアイデア。誰が出すかな」と笑います。アイデアがあれば、新しい取り組みにすぐに着手できて、すぐ結果が出るため失敗してもすぐに軌道修正することが可能な土台が整いました。DXに次々と挑戦できます。
さらに先は当初の枠を超える可能性も見えてきています。飯塚さんは「オンプレにある各種システムをEPモダンデータプラットフォームと連携することをIT部門と調整しているところです。現状では弊社のデータサイエンティストたちのデータ分析環境がクラウドではなく、性能に制限がありますので」と言います。EPモダンデータプラットフォームは東電EPにおけるデータ分析環境の中心的な役割へと拡張していくことになりそうです。








